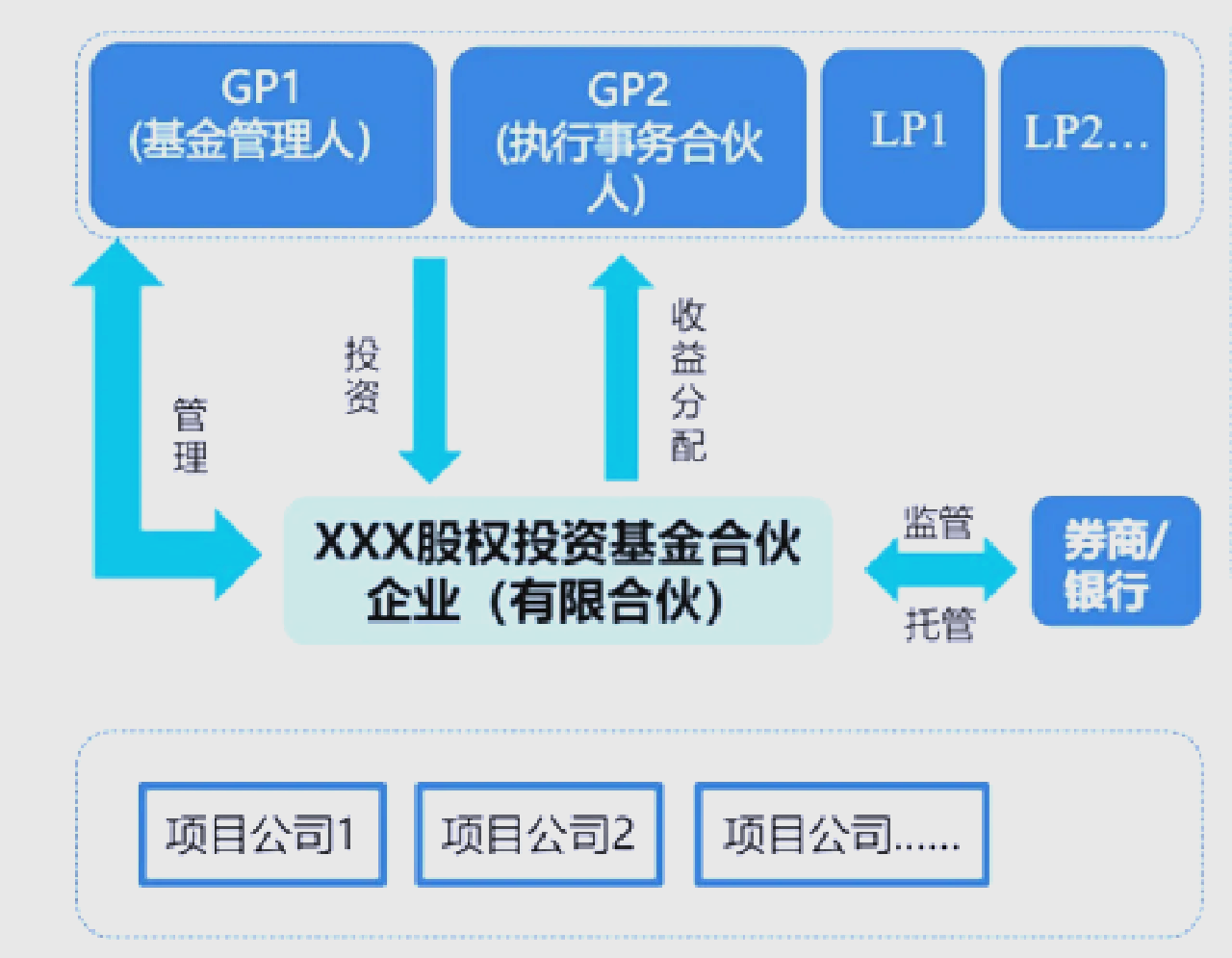
私募股權投資退出機制全解析 IPO、并購、新三板掛牌等七大路徑詳解

私募股權投資(Private Equity,簡稱PE)的核心在于“投資—管理—退出”的完整閉環,而退出環節是決定最終收益的關鍵。本文將系統解析私募股權投資的七大主流退出機制,并探討融資咨詢服務在其中的重要作用。
一、首次公開募股(IPO)
IPO被視為最理想的退出方式,指被投資企業通過首次公開發行股票并在證券交易所上市交易,私募基金通過二級市場減持實現退出。其優勢在于:1)通常能獲得較高估值溢價;2)提升基金品牌影響力;3)流動性較好。但IPO也存在審核周期長、成本高、受市場環境影響大等挑戰。注冊制改革的推進正為PE/VC的IPO退出創造更有利環境。
二、并購退出(M&A)
并購退出指將所持股權出售給產業投資者或財務投資者,是歐美市場最主流的退出方式。其特點包括:1)交易相對靈活,退出周期較短;2)可一次性實現完全退出;3)適合尚未達到上市標準但擁有核心技術或市場份額的企業。隨著產業整合加速,并購退出在國內的重要性日益凸顯。
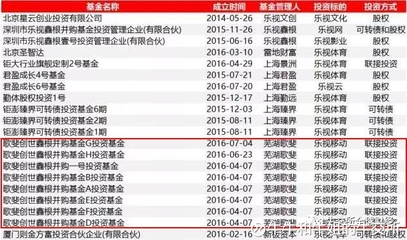
三、新三板掛牌及北交所上市
新三板(全國中小企業股份轉讓系統)及北交所為中小企業提供了新的資本化路徑:1)新三板掛牌后可進行協議轉讓或做市交易;2)符合條件的掛牌企業可申請北交所上市;3)作為IPO的預備階段,有助于規范公司治理。盡管流動性曾受挑戰,但北交所的設立為“專精特新”企業提供了更清晰的上市通道。
四、股權轉讓
股權轉讓包括老股轉讓給其他投資機構、管理層或員工等:1)S基金(Secondary Fund)交易日益活躍,為PE提供了中途退出渠道;2)企業管理層收購(MBO)也是常見方式;3)交易條款相對靈活,但估值可能低于IPO。
五、回購退出
回購退出指由被投資企業或其股東、管理層按約定價格回購股權:1)通常作為投資協議中的保障性條款;2)適用于企業發展未達預期或基金存續期屆滿的情況;3)收益相對穩定但回報率通常有限。
六、借殼上市
借殼上市指非上市公司通過收購已上市公司控制權,注入自身資產實現間接上市:1)可規避IPO的漫長審核;2)但需承擔殼成本及合規風險;3)隨著注冊制推行,傳統借殼模式吸引力下降,但產業整合式的“類借殼”仍存空間。
七、清算退出
清算作為最后的選擇,適用于企業經營失敗時:1)通過破產程序收回殘值;2)雖有優先清償權,但回收率通常較低;3)凸顯了投前風控和投后管理的重要性。
八、融資咨詢服務的協同價值
專業的融資咨詢服務在退出過程中扮演多重角色:1)協助設計最優退出方案及時間表;2)提供估值分析、財務建模支持;3)對接券商、律所、會計師事務所等中介機構;4)在并購交易中擔任財務顧問,協助談判;5)為重組、借殼等復雜交易提供結構化設計。
私募股權退出機制的選擇需綜合考量基金存續期限、企業發展階段、市場環境及條款約束等多重因素。多元化退出策略(如“IPO+并購”組合)正成為行業趨勢。無論是哪種退出路徑,提前規劃、專業執行以及與融資咨詢服務的深度協同,都是實現投資價值最大化的關鍵保障。
如若轉載,請注明出處:http://www.ph2008.cn/product/71.html
更新時間:2026-06-19 10:16:29